[Spring + Redis] 스핀락과 분산락에 대하여
들어가기 전
이번 포스팅에서는 Redis에서 제공하는 스핀락과 분산락에 대해서 알아보겠습니다.
예제에서 ReentrantLock, Mysql 네임드 락, Redis를 사용할 예정인데 ReentrantLock에 대해서 모르시는 분은 아래 포스팅을 참고 후 이어서 이번 포스팅을 읽으시는 것을 추천드리겠습니다.
[Java] synchronized와 ReentrantLock에 대해서
들어가기 전멀티 스레드 환경에서 동시에 접근하면 데이터 무결성이 깨질 수 있습니다.이러한 현상을 방지하기 위해 synchronized와 ReentrantLock을 사용해서 임계 영역에 하나의 자원만 접근하게 하
hoestory.tistory.com
Redis가 무엇인지 궁금하신 분은 아래 포스팅을 참고하시기 바랍니다.
[Redis] Redis 개념 및 특징
들어가기 전 Redis는 Cache와 연관이 되어 있어 Cache에 대해 먼저 알아보고 Redis의 개념과 특징에 대해 알아보겠습니다. Cache란? 자주 사용하는 데이터를 메모리에 미리 복사해 놓는 임시 장소입니다
hoestory.tistory.com
먼저 스핀락과 분산락이 무엇인지에 대해 알아보고 예제를 통해서 활용하는 방법에 대해서 알아보겠습니다.
예제는 Redis를 적용하기 전과 후에 대해서 다룰 예정입니다.
스핀락
스핀락은 특정 스레드가 임계 영역에 접근 시도할 때 이미 락을 획득한 다른 스레드가 있을 경우 다른 스레드의 작업이 완료될 때까지 계속해서 락을 획득하기 위해 시도를 하는 것입니다.
동작 과정
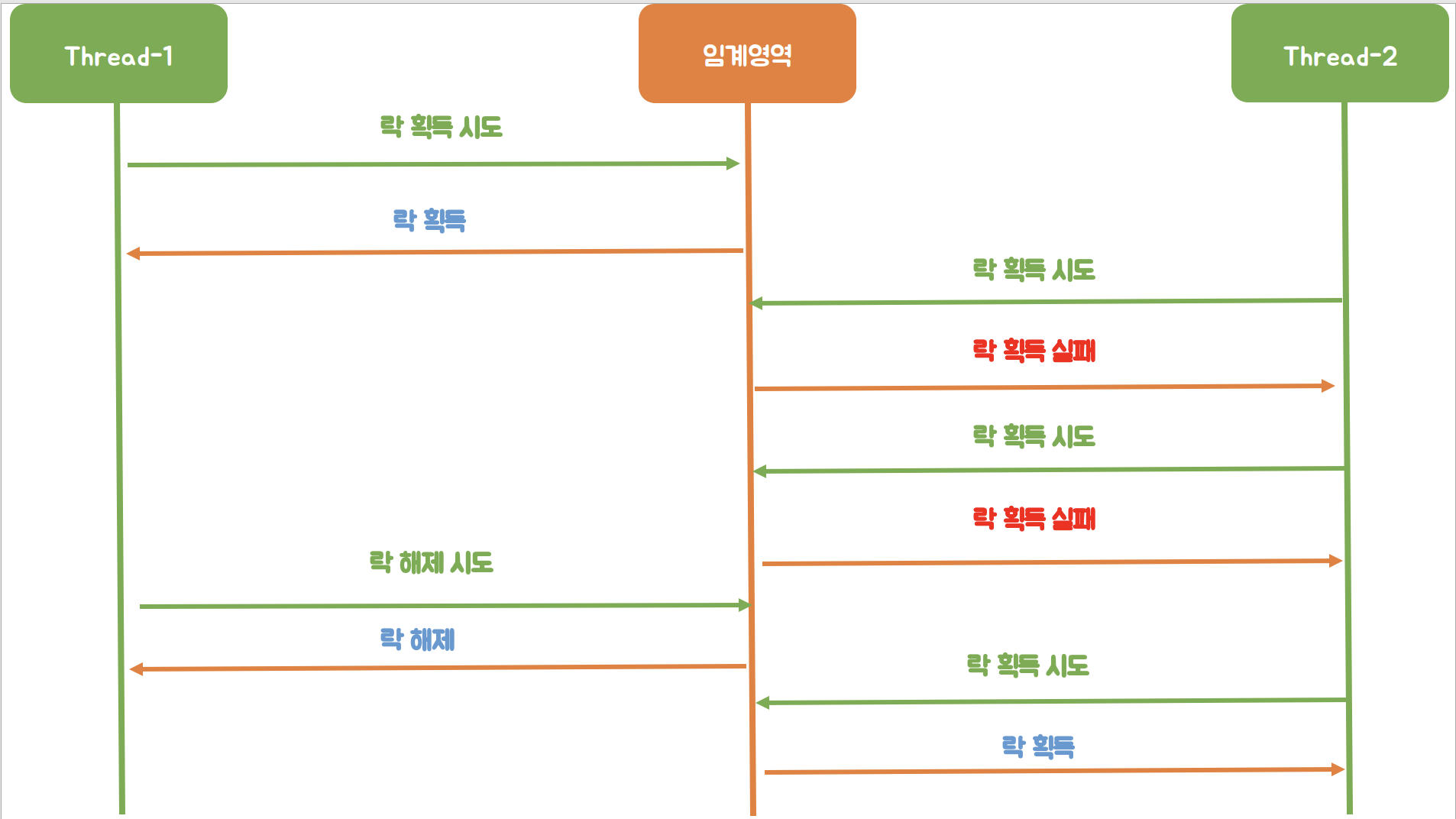
하나의 스레드가 임계 영역에 접근하여 락을 획득한 뒤 다른 스레드가 임계영역에 접근하려고 하였으나 이미 락을 획득한 스레드가 있어 락 획득을 실패하는 것을 확인할 수 있습니다.
락 획득을 실패를 한 뒤 스레드의 작업이 끝나는 것이 아니라 락을 획득할 때까지 계속해서 시도를 합니다.
그리고 락을 획득했던 스레드가 락을 해제하면 락 획득을 시도했던 스레드가 락을 획득하는 것을 확인할 수 있습니다.
분산락
멀티 스레드 환경에서 동시에 여러 스레드가 임계 영역에 접근을 시도를 할 때 데이터의 정합성을 지키기 위한 락 종류 중 하나입니다.
스프링에서는 싱글 스레드가 아닌 멀티 스레드 환경이기 때문에 임계영역에 하나의 스레드만 접근할 수 있는 방법으로 데이터의 정합성을 보장해줘야 하는데 자바에서 제공하는 synchronized를 사용하여 정합성을 보장해 줄 수 있지만 현재 운영 중인 서비스가 커져서 한대의 서버가 아닌 여러 대의 서버를 운영하게 된다면 synchronized만으로 데이터의 정합성을 보장하기가 어렵습니다.
그래서 사용할 수 있는 방법은 *MySQL 네임드 락, Redis 등을 이용하여 분산락을 적용할 수 있습니다.
Mysql 네임드 락이란?
세션이 시작될 때 특정 이름에 락을 걸어 다른 세션에서 해당 이름으로 락을 획득하려고 시도를 할 때 대기하게 하는 기능입니다.
네임드 락을 관리하는 방법은 세션 단위입니다.
세션이 종료되면 해당 세션이 보유한 모든 락도 자동으로 해제가 됩니다.
지금까지 스핀락과 분산락에 대해서 알아보았습니다. 이제 예제를 통해서 적용하는 방법에 대해서 알아보겠습니다.
스핀락 예제에서 사용할 커스텀 인터페이스
public interface SpinLock {
void executeSpinLock(Counter counter);
}스핀락 - ReentrantLock 활용
public class Counter {
private int count;
private Lock lock = new ReentrantLock();
public void increaseCounter() {
count += 1;
}
public int getCount() {
return count;
}
}
- increaseCounter 메서드를 통해 count 증가
- getCount : Counter 객체의 count값 조회
public class JavaSpinLock implements SpinLock {
private Lock lock = new ReentrantLock();
@Override
public void executeSpinLock(Counter counter) {
while (true) {
boolean result = lock.tryLock();
if (result) {
break;
}
System.out.println("락 획득 실패 스레드명 : " + Thread.currentThread().getName());
}
try {
System.out.println(
"락 획득 성공 스레드명 : " + Thread.currentThread().getName());
counter.increaseCounter();
} finally {
System.out.println(
"락 해제 스레드명 : " + Thread.currentThread().getName());
lock.unlock();
}
}
}
class JavaSpinLockTest {
@Test
void executeJavaSpinLock() throws InterruptedException {
int threadCount = 5;
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
Counter counter = new Counter();
CountDownLatch doneSignal = new CountDownLatch(threadCount);
SpinLock spinLock = new JavaSpinLock();
for (int i = 0; i < threadCount; i++) {
executorService.execute(() -> {
spinLock.executeSpinLock(counter);
doneSignal.countDown();
});
}
doneSignal.await();
executorService.shutdown();
Assertions.assertThat(counter.getCount()).isEqualTo(threadCount);
}
}
코드 설명
스핀락 적용
while (true) {
boolean result = lock.tryLock();
if(result) {
break;
}
System.out.println("락 획득 실패 스레드명 : " + Thread.currentThread().getName());
}
- while(true)를 통해 무한 반복
- lock.tryLock을 통해 현재 락을 획득한 스레드가 있는지 확인
- 락을 획득한 스레드가 없으면 락을 획득하면서 true
- 락을 획득한 스레드가 존재하면 false 반환
임계영역 접근
try {
System.out.println("락 획득 성공 스레드명 : " + Thread.currentThread().getName());
counter.increaseCounter();
} finally {
System.out.println("락 해제 스레드명 : " + Thread.currentThread().getName());
lock.unlock();
}
- 락을 획득한 스레드가 임계영역에 접근하여 counter.increaseCounter() 호출
- 락을 획득한 스레드가 작업이 완료된 후 lock.unlock을 통해 락 해제
위 코드를 실행시키면 모든 스레드가 락 획득을 실패하더라도 지속적으로 획득하기 위해 시도하는 모습을 확인할 수 있습니다.
그 후 모든 스레드가 락 획득 후 임계 영역에 접근을 해야 프로세스가 끝나는 것을 확인할 수 있습니다.
스핀락 - Redis(Lettuce) 활용
@Component
@RequiredArgsConstructor
public class RedisRepository {
private final RedisTemplate<String, Object> redisTemplate;
public boolean spinLock(String keyName) {
String redisKey = getKey(keyName);
return redisTemplate.opsForValue().setIfAbsent(redisKey, "0");
}
public void unlock(String ketName) {
redisTemplate.delete(getKey(ketName));
}
private String getKey(String keyName) {
return String.format("spinLock:%s", keyName);
}
}
- setIfAbsent : redis의 SETNX의 명령어로 이미 키 값이 존재하면 false(0)를 반환하고 키 값이 존재하지 않으면 true(1)을 반환합니다.
@Service
@RequiredArgsConstructor
public class RedisSpinLock implements SpinLock {
private final RedisRepository redisRepository;
private final static String KEY_NAME = "counter";
@Override
public void executeSpinLock(Counter counter) {
while(!redisRepository.spinLock(KEY_NAME)) {
System.out.println("락 획득 실패 스레드명 : " + Thread.currentThread().getName());
}
try {
System.out.println("락 획득 성공 스레드명 : " + Thread.currentThread().getName());
counter.increaseCounter();
} finally {
System.out.println("락 해제 스레드명 : " + Thread.currentThread().getName());
redisRepository.unlock(KEY_NAME);
}
}
}
- redisRepository.spinLock(KEY_NAME) : redis에 키 값이 존재하면 false(0) 반환, 존재하지 않으면 true(1)을 반환하여 스핀락 적용
- redisRepository.unlock(KEY_NAME) : 락을 획득한 redis 키 값 삭제하여 락 해제
@SpringBootTest
class RedisSpinLockTest {
@Autowired
private RedisSpinLock redisSpinLock;
@Test
void executeSpinLock() throws InterruptedException {
int threadCount = 5;
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
Counter counter = new Counter();
CountDownLatch doneSignal = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(() -> {
redisSpinLock.executeSpinLock(counter);
doneSignal.countDown();
});
}
doneSignal.await();
executorService.shutdown();
Assertions.assertThat(counter.getCount()).isEqualTo(threadCount);
}
}

지금까지 자바의 ReentrantLock, Redis를 이용하여 스핀락 예제를 알아보았습니다.
이제 스핀락의 장단점에 대해서 알아보고 어떤 상황에 따라 ReentrantLock, Redis를 사용해야 되는지 알아보겠습니다.
스핀락의 장점
- 스레드의 상태를 변경하지 않고 CPU를 계속 점유하고 있기 때문에 컨텍스트 스위칭으로 인한 오버헤드가 발생하지 않습니다.
- 스레드가 락을 점유하고 있는 시간이 짧다면 컨텍스트 스위칭 비용을 아끼면서 효율적으로 처리할 수 있습니다.
스핀락의 단점
- 별도로 지정한 Time Out을 지정하지 않기 때문에 CPU 비용이 많이 발생합니다.
- 여러 스레드가 동시에 수행되면 CPU가 다 빼앗기고 시스템 전체 성능이 나빠질 수 있습니다.
ReentrantLock, Redis를 이용한 스핀락 어떤 상황에서 적용하여야 하는가?
ReentrantLock 같은 경우에는 운영 중인 서비스를 한대의 서버로 운영중일경우에 사용에 적합합니다.
만약 여러 대의 서버를 운영 중인 서비스에서 ReentrantLock을 활용하여 스핀락을 적용하게 된다면 어떻게 되는지 아래 그림으로 알아보겠습니다.

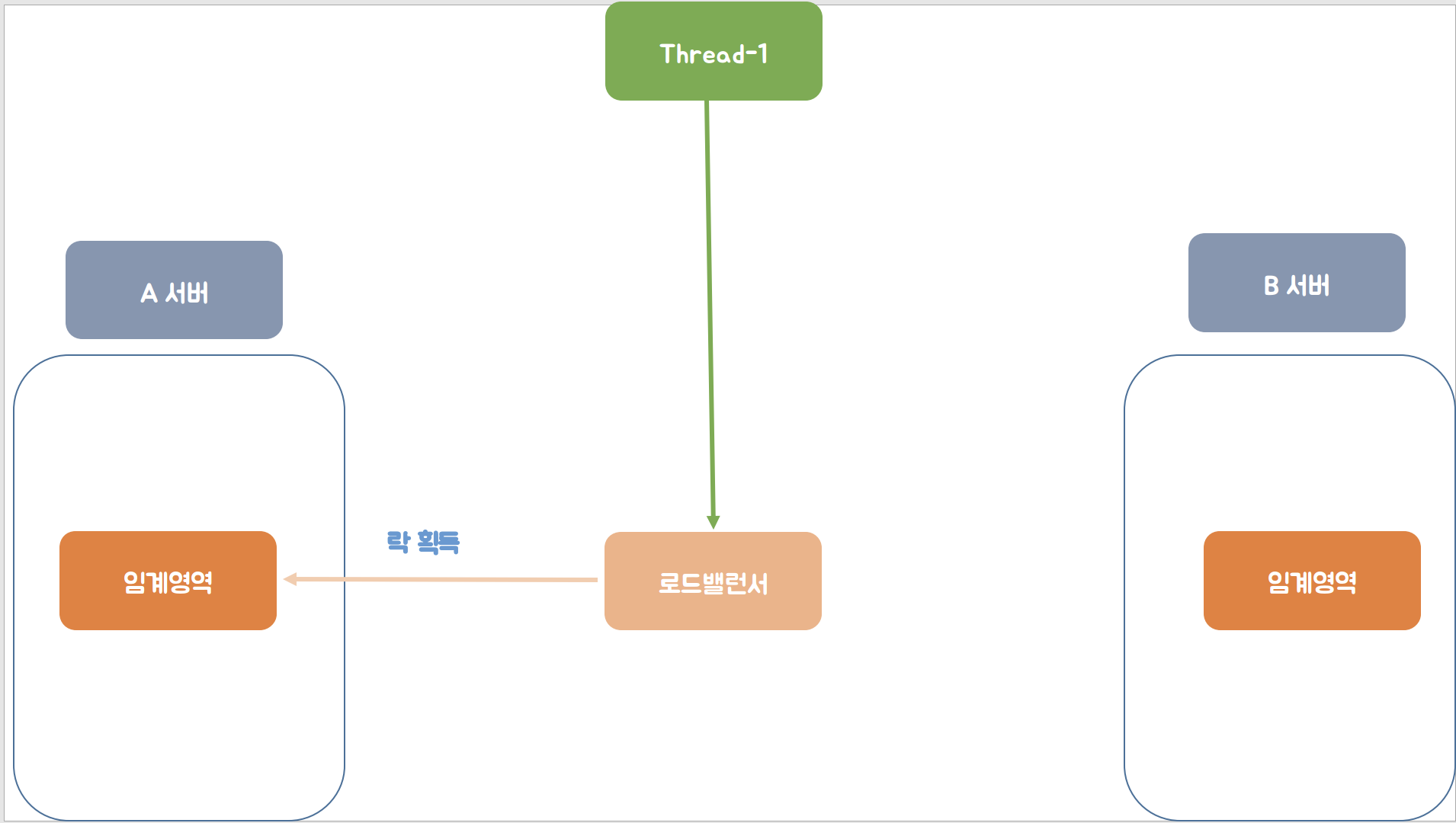
첫 번째 스레드의 요청이 로드 밸런서를 통해 A서버에게 보내서 A서버의 임계영역에 접근하여 락 획득하는 모습을 확인할 수 있습니다.
이어서 두 번째의 스레드의 요청이 와서 이번에는 로드 밸런서에서 B서버로 요청을 보내어 B서버의 임계영역에 접근하여 락을 획득하는 모습을 확인할 수 있습니다.
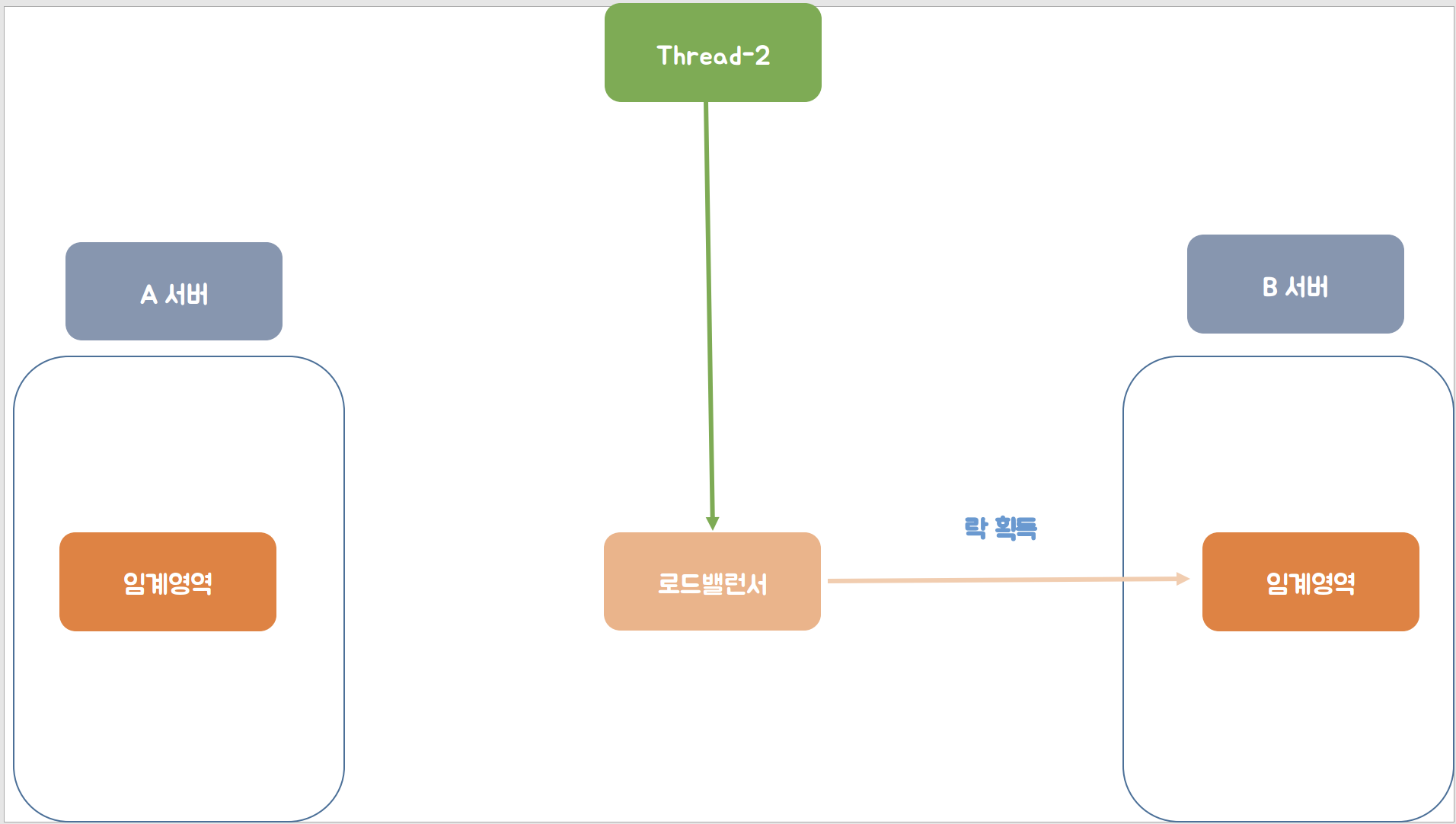
위 예시처럼 서버가 여러 대일경우에는 하나의 서버에서 임계영역에 접근하여 락을 획득하였다고 하더라도 다른 서버에는 락을 획득한 스레드가 없어서 동시성 문제가 발생하는 것을 확인할 수 있습니다.
이런 상황에서는 Redis를 이용하여 스핀락을 구현하여 동시성 이슈를 방지하는 게 좋습니다.
여러대를 운영 중인 서비스에서 Redis를 도입하여 스핀락을 적용하면 어떻게 되는지 아래 그림을 통해 알아보겠습니다.
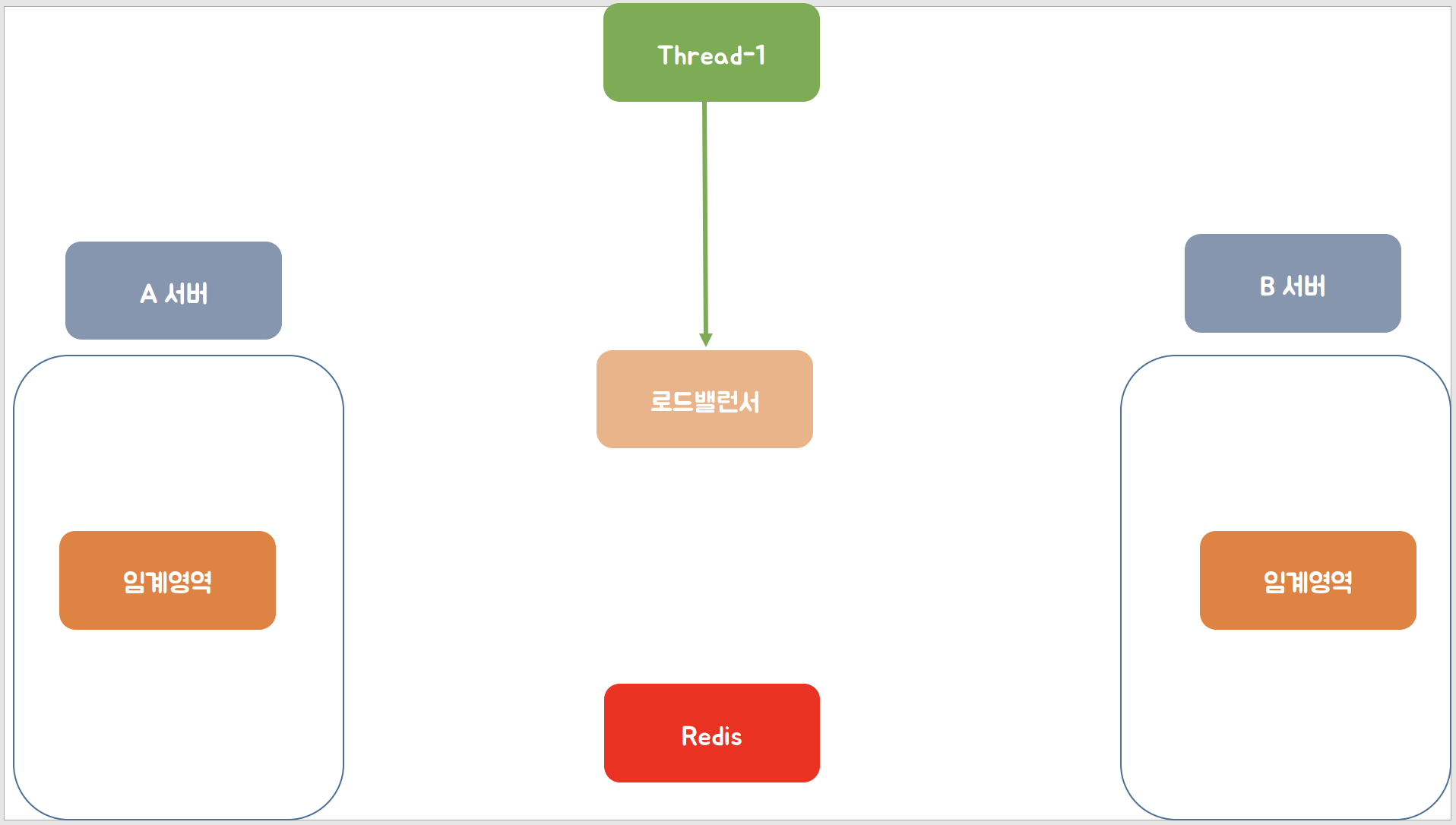
첫 번째 스레드의 요청이 로드 밸런서를 통해 A서버에게 보내서 A서버의 임계영역에 접근하여 락 획득하는 모습을 확인할 수 있습니다.
그리고 A 서버에서 "lock:counter"라는 키를 이용하여 Redis와 통신하여 락을 획득하는 모습을 확인할 수 있습니다.
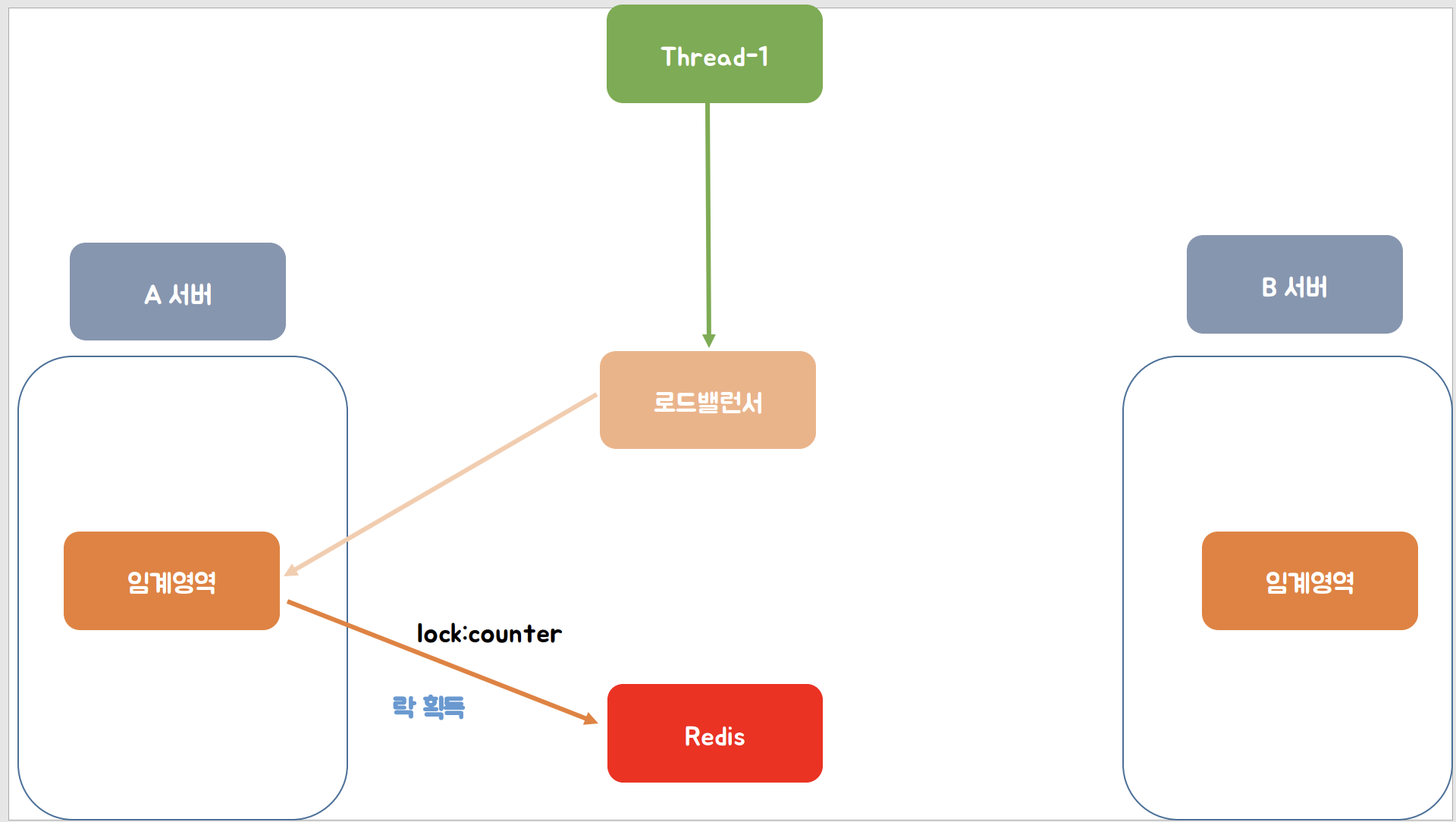
이어서 두 번째의 스레드의 요청이 와서 이번에는 로드 밸런서에서 B서버로 요청을 보내어 B서버의 임계영역에 접근하여 Redis에 "lock:counter"키 값을 통신하려고 하는데 이미 값이 존재하여 락 획득 실패하는 것을 확인할 수 있습니다.
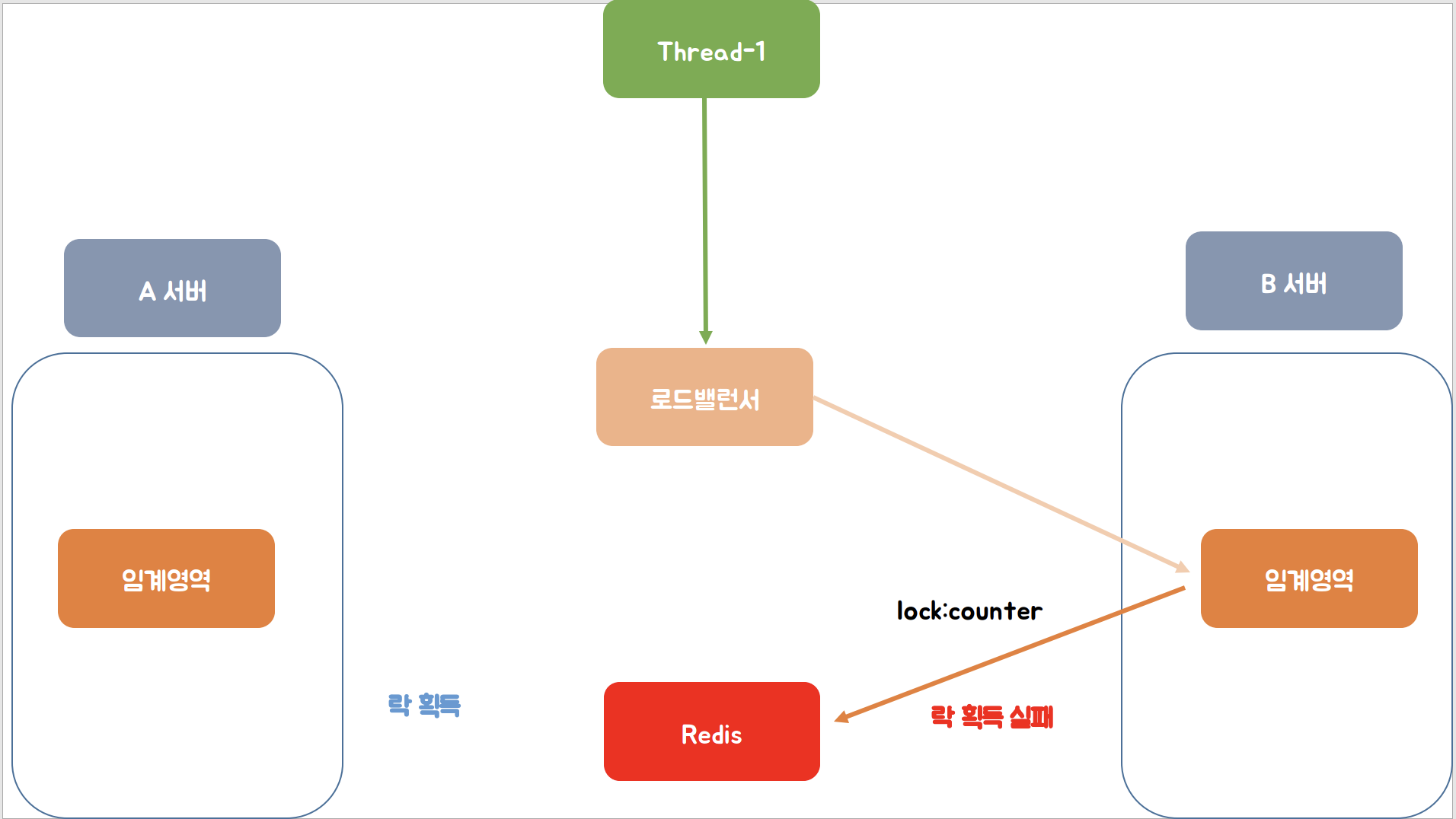
이와 같이 하나의 서버에서는 자바에서 제공하는 ReentrantLock을 사용하여 스핀락을 구현해도 되지만 여러 개의 서버를 운영중일경우에는 Redis와 같은 기술을 사용하여 스핀락을 활용할 수 있습니다.
분산락 - MySQL 네임드락 활용
public interface CounterRepository extends JpaRepository<Counter, Long> {
@Query(value = """
SELECT GET_LOCK(:lockName, :second)
""", nativeQuery = true)
int acquireLock(@Param("lockName") String lockName, @Param("second") long second);
@Query(value = """
SELECT RELEASE_LOCK(:lockName)
""", nativeQuery = true)
int releaseLock(@Param("lockName") String lockName);
}
- GET_LOCK을 통해 매개변수로 들어오는 "lockName"에 대해서 네임들 락을 획득합니다.
- RELEASE_LOCK을 통해 "lockName"으로 네임드 락이 걸린 커넥션에 대해서 락을 해제합니다.
@Service
@RequiredArgsConstructor
public class CounterService {
private final CounterRepository counterRepository;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public Counter update(Long counterId) {
Counter counter = counterRepository.findById(counterId)
.orElseThrow(IllegalArgumentException::new);
counter.increaseCounter();
return counter;
}
}
@Service
@RequiredArgsConstructor
public class MySqlNamedLock {
private final static String MYSQL_NAME_LOCK_NAME = "counter";
private final CounterRepository counterRepository;
private final CounterService counterService;
public void updateCounter() {
String currentName = Thread.currentThread().getName();
try {
System.out.printf("락 시도 스레드명 : %s\n", currentName);
counterRepository.acquireLock(MYSQL_NAME_LOCK_NAME, 2);
System.out.printf("락 획득 스레드명 : %s\n", currentName);
counterService.update(1L);
}finally {
System.out.printf("락 해제 스레드명 : %s\n", currentName);
counterRepository.releaseLock(MYSQL_NAME_LOCK_NAME);
}
}
}
- acquireLock을 통해 MySQL 네임드 락 획득
- releaseLock을 통해 MySQL 네임드 락 해제
@SpringBootTest
class MySqlNamedLockTest {
@Autowired
private MySqlNamedLock mySqlNamedLock;
@Autowired
private CounterRepository counterRepository;
@BeforeEach
public void init() {
counterRepository.save(new Counter(1L));
}
@AfterEach
public void clear() {
counterRepository.deleteAllInBatch();
}
@Test
void executeMySqlNamedLock() throws InterruptedException {
int threadCount = 10;
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
CountDownLatch doneSignal = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(
() ->
{
mySqlNamedLock.updateCounter();
doneSignal.countDown();
}
);
}
doneSignal.await();
executorService.shutdown();
Counter counter = counterRepository.findById(1L).get();
Assertions.assertThat(counter.getCount()).isEqualTo(10);
}
}
위 테스트 코드를 실행하면 아래와 같이 성공하는 것을 확인할 수 있습니다.
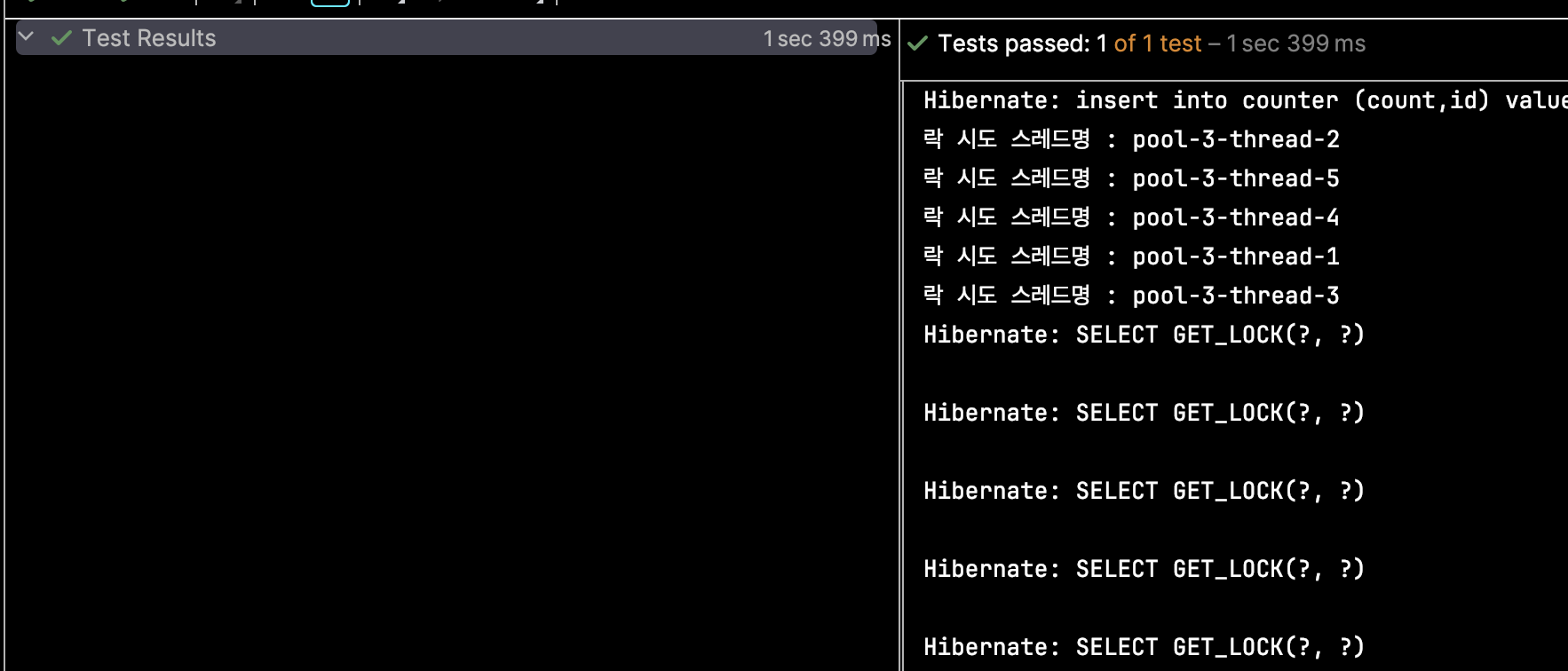
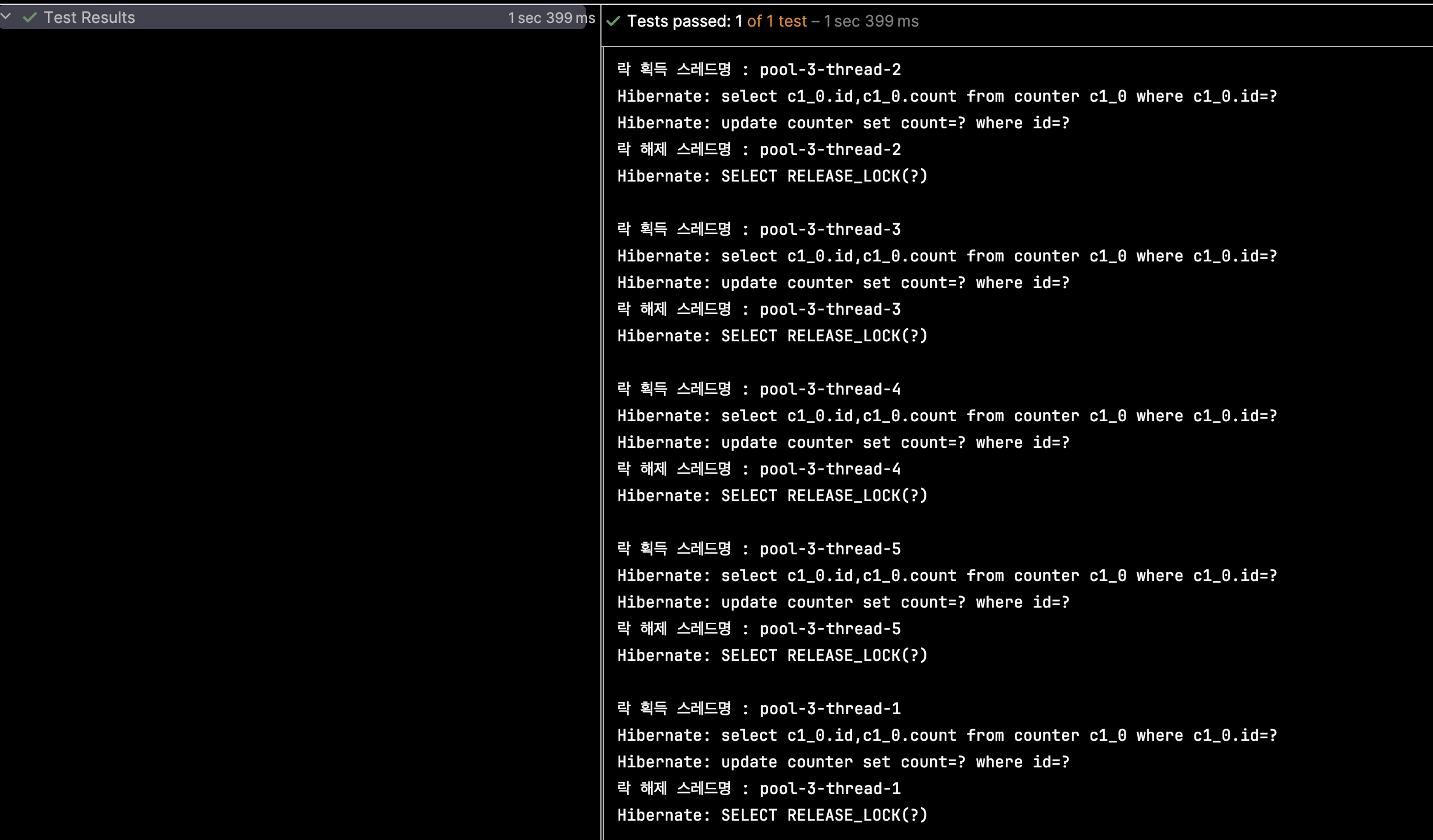
테스트한 결과와 로그를 보여주기 위해서 적은 양의 스레드로 생성하여 테스트하였지만 많은 스레드로 설정을 하였어도 똑같은 결과가 나올 것입니다.
GET_LOCK을 통해서 MySQL 네임드 락을 획득하고 작업이 끝난 락은 RELEASE_LOCK을 통해 해제되고 대기하고 있던 스레드가 락을 획득하는 것을 확인할 수 있습니다.
*참고
이번 포스팅은 스핀락과 분산락에 대해 알아보고 예제를 통해 락 적용하는 방법에 대한 내용이기 때문에 MySQL 네임드 락에 대한 설명은 자세히 하지 않았습니다.
분산락 - Redis 활용
Redisson 설정
@Configuration
public class RedisConfig {
@Value("${spring.data.redis.host}")
private String host;
@Value("${spring.data.redis.port}")
private int port;
private final String REDSISSON_PREFIX = "redis://";
@Bean
public RedissonClient redissonClient() {
Config config = new Config();
config.useSingleServer().setAddress(String.format("%s%s:%d", REDSISSON_PREFIX, host, port));
return Redisson.create(config);
}
}
@Service
@RequiredArgsConstructor
public class RedissonCounterService {
private final CounterRepository counterRepository;
@Transactional
public Counter update(Long counterId) {
Counter counter = counterRepository.findById(counterId)
.orElseThrow(IllegalArgumentException::new);
counter.increaseCounter();
return counter;
}
}
@Service
@RequiredArgsConstructor
public class RedissonLock {
private final RedissonCounterService redissonCounterService;
private final RedissonClient redissonClient;
private static final String REDISSON_COUNT_LOCK_PREFIX = "count:";
public void executeRedissonLock() {
long countId = 1L;
RLock lock = redissonClient.getLock(
String.format("%s%d", REDISSON_COUNT_LOCK_PREFIX, countId));
String currentName = Thread.currentThread().getName();
try {
boolean isLock = lock.tryLock(3, 1, TimeUnit.SECONDS);
if (!isLock) {
System.out.printf("락 실패 스레드명 : %s", currentName);
return;
}
System.out.printf("락 획득 스레드명 : %s", currentName);
redissonCounterService.update(countId);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
}
- lock.tryLock(waitTime, leaseTime, TimeUnit) : waitTime은 락을 획득하기 위해 대기하는 시간을 나타내고 leaseTime은 락을 획득한 뒤 락 점유하고 있는 시간을 나타냅니다.
- lock.unlock : 작업이 끝나면 락을 해제합니다.
@SpringBootTest
class RedissonLockTest {
@Autowired
RedissonLock redissonLock;
@Autowired
CounterRepository counterRepository;
@BeforeEach
public void init() {
counterRepository.save(new Counter(1L));
}
@AfterEach
public void clear() {
counterRepository.deleteAllInBatch();
}
@Test
void executeRedissonLock() throws InterruptedException {
int threadCount = 10;
ExecutorService executorService = Executors.newFixedThreadPool(threadCount);
CountDownLatch countDownLatch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.execute(() -> {
redissonLock.executeRedissonLock();
countDownLatch.countDown();
});
}
countDownLatch.await();
executorService.shutdown();
// then
Counter counter = counterRepository.findById(1L).get();
Assertions.assertThat(counter.getCount()).isEqualTo(threadCount);
}
}
위 테스트 코드를 수행하면 아래와 같이 테스트가 성공하는 것을 확인할 수 있습니다.
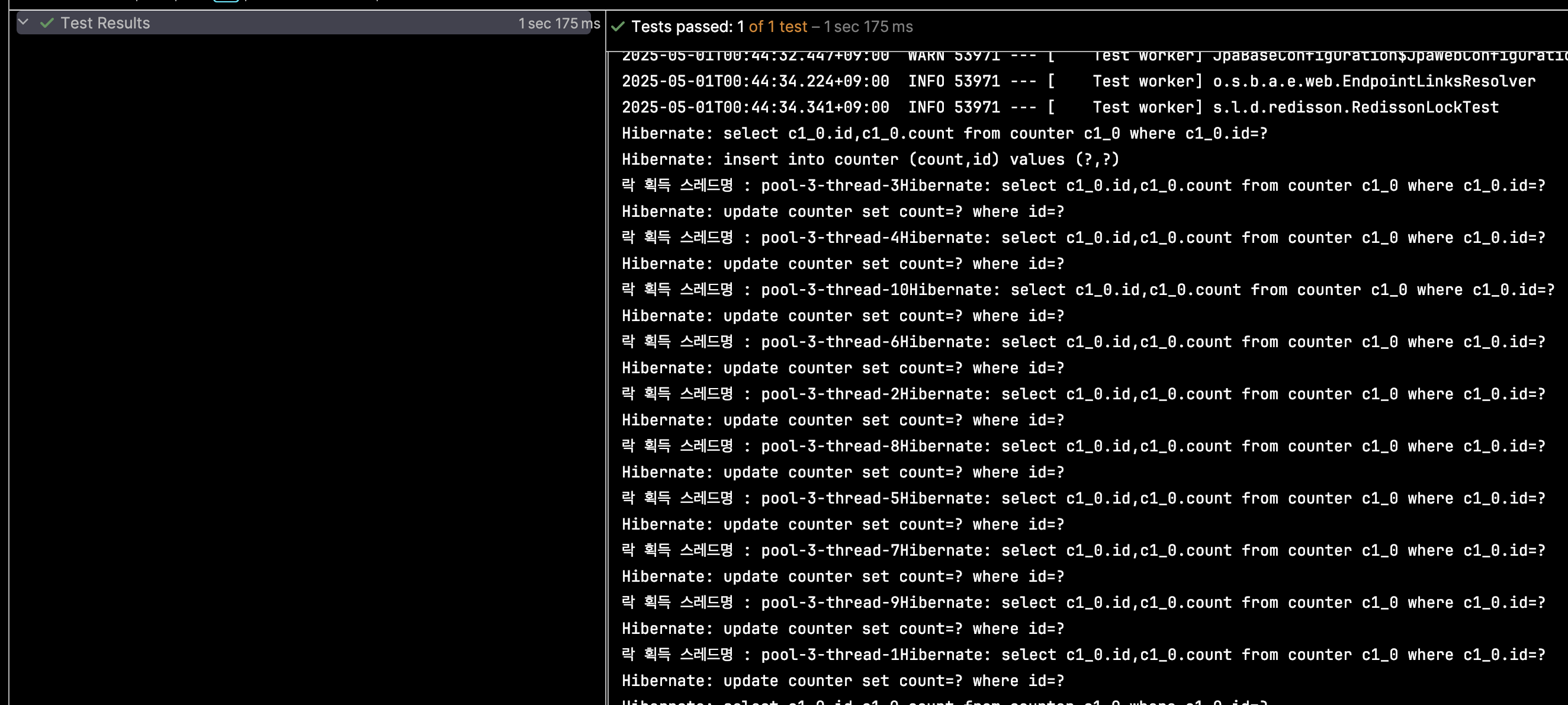
이와 같이 Redisson을 이용하여 분산락을 구현하는 방법에 대해서 알아보았습니다.
그런데 Redisson을 활용하여 분산락을 구현할 때 주의할 점이 있습니다.
Redisson을 이용하여 분산락을 구현할 때 주의할 점
위 예제에서 사용한 RedissonLock과 RedissonCounterSerivce에서 트랜잭션을 왜 RedissonLock에 설정하지 않고
RedissonCounterService에 설정하였는지 의문이 드시는 분이 계실 수 있습니다.
만약 RedissonLock에 트랜잭션을 설정하게 되면 동시성 이슈가 발생합니다.
이유는 트랜잭션을 설정하기 위해서 사용하는 @Transactional 때문입니다.
@Transactional은 AOP 방식으로 동작하게 되는데 로직이 시작하는 시점에 트랜잭션이 시작되고 로직이 끝나는 시점에 커밋 또는 롤백을 진행합니다.
그런데 락을 획득한 스레드가 락을 해제하는 시점은 finally이 수행될 때 락을 해제하게 됩니다.
락을 해제하는 시점이 커밋 또는 롤백 이전에 수행되기 때문에 동시성 이슈가 발생하게 됩니다.
그래서 RedissonCounterService에 트랜잭션을 설정하였고 로직이 끝나면 update 쿼리가 수행되도록 설정하였습니다.
분산락을 적용할 때 언제 MySQL 네임드락을 사용해야 하고 Redisson을 사용해야 하는가?
아래 질문 중 하나라도 Yes일 경우에 Redisson을 사용하고 그렇지 않고 모두 No일 경우에는 MySQL 네임드 락을 사용하시는 것을 추천드리겠습니다.
- 인프라를 구축할 만큼 금전적으로 여유가 있는가?
- Redis를 이미 사용 중인가?
첫째, Redis를 사용하기 위해서는 인프라를 구축해야 하는데 이 과정에서 비용이 발생하게 됩니다.
비용으로 인해 Redis를 도입하기 어려운 환경이라면 MySQL 네임드 락을 사용하시는 것을 추천드리겠습니다.
둘째, 이미 Redis를 사용하고 있다면 무조건적으로 Redisson을 사용하는 게 아닌 MySQL 네임드 락과 Redisson을 상황에 맞게 적용하시는 것을 추천드리겠습니다.
'Spring+Redis' 카테고리의 다른 글
| Rate Limit에 대하여(토큰, 누출, 고정 윈도우 - Spring + Redis) (0) | 2025.10.10 |
|---|