[JPA] 2차 캐시란?
들어가기 전
이번 포스팅에서는 JPA의 1차 캐시가 아닌 2차 캐시에 대해 알아보겠습니다.
필자는 지금까지 JPA의 2차 캐시에 대한 존재를 모르고 개발을 하고 있었습니다. 최근에 2차 캐시라는 단어를 우연히 듣게 되어 이렇게 블로그를 쓰게 되었습니다.
일단 2차 캐시에 대해 알아보기 전에 1차 캐시에 대해 알아볼 것이고 캐시라는 단어가 생소한 분들께서는 아래 포스팅을 읽고 이번 포스팅을 보면 좋을 거 같습니다.
https://hoestory.tistory.com/46
[Redis] Redis 개념 및 특징
들어가기 전 Redis는 Cache와 연관이 되어 있어 Cache에 대해 먼저 알아보고 Redis의 개념과 특징에 대해 알아보겠습니다. Cache란? 자주 사용하는 데이터를 메모리에 미리 복사해 놓는 임시 장소입니다
hoestory.tistory.com
1차 캐시란
영속성 컨텍스트의 특징 중 하나인 1차 캐시는 같은 영속성 컨텍스트 내에서 같은 엔티티를 조회를 하면 데이터베이스에 접근하지 않고 1차 캐시에 있는 엔티티를 반환합니다.
1차 캐시동작과정
1차 캐시에 조회하려는 값이 존재하지 않을 경우

- id값으로 엔티티를 조회합니다.
- 조회하려는 엔티티가 1차 캐시에 존재하지 않으면 데이터베이스에 접근을 합니다.
- 데이터베이스는 요청에 맞는 결과값을 반환을 합니다.
- 데이터베이스로부터 반환받은 값을 1차 캐시에 보관합니다.
- 엔티티를 반환합니다.
public void firstSelect() {
System.out.println("1차 캐시에 존재하지 않을경우");
accountRepository.findById(1L).get();
}
1차 캐시에 조회하려는 값이 존재하는 경우

- id값으로 엔티티를 조회합니다.
- 조회하려는 값이 1차 캐시에 존재합니다.
- 1차 캐시에 엔티티가 있어 데이터베이스에 접근하지 않고 1차 캐시에서 바로 반환해 줍니다.
public void secondSelect() {
System.out.println("1차 캐시에 존재하지 않을경우");
accountRepository.findById(1L).get();
System.out.println("1차 캐시에 존재 할 경우");
accountRepository.findById(1L).get();
}
지금까지 1차 캐시에 대해 알아보았습니다. 이제부터 2차 캐시에 대해 알아보겠습니다.
2차 캐시란
애플리케이션 범위에서 공유하는 캐시를 JPA에서 공유 캐시 또는 2차 캐시라고 부릅니다.
2차 캐시는 애플리케이션 종료 시까지 유지합니다.
@Service
@RequiredArgsConstructor
@Transactional
public class CacheExampleService {
private final AccountRepository accountRepository;
public Account findById(Long id) {
return accountRepository.findById(id).get();
}
}
@SpringBootTest
class CacheExampleServiceTest {
@Autowired
private AccountRepository accountRepository;
@Autowired
private CacheExampleService cacheExampleService;
@Test
void test() throws InterruptedException {
// 1차
Account savedAccount = accountRepository.save(new Account("test", 27, 10000));
Account account = cacheExampleService.findById(1L);
Account account2 = cacheExampleService.findById(1L);
}
}
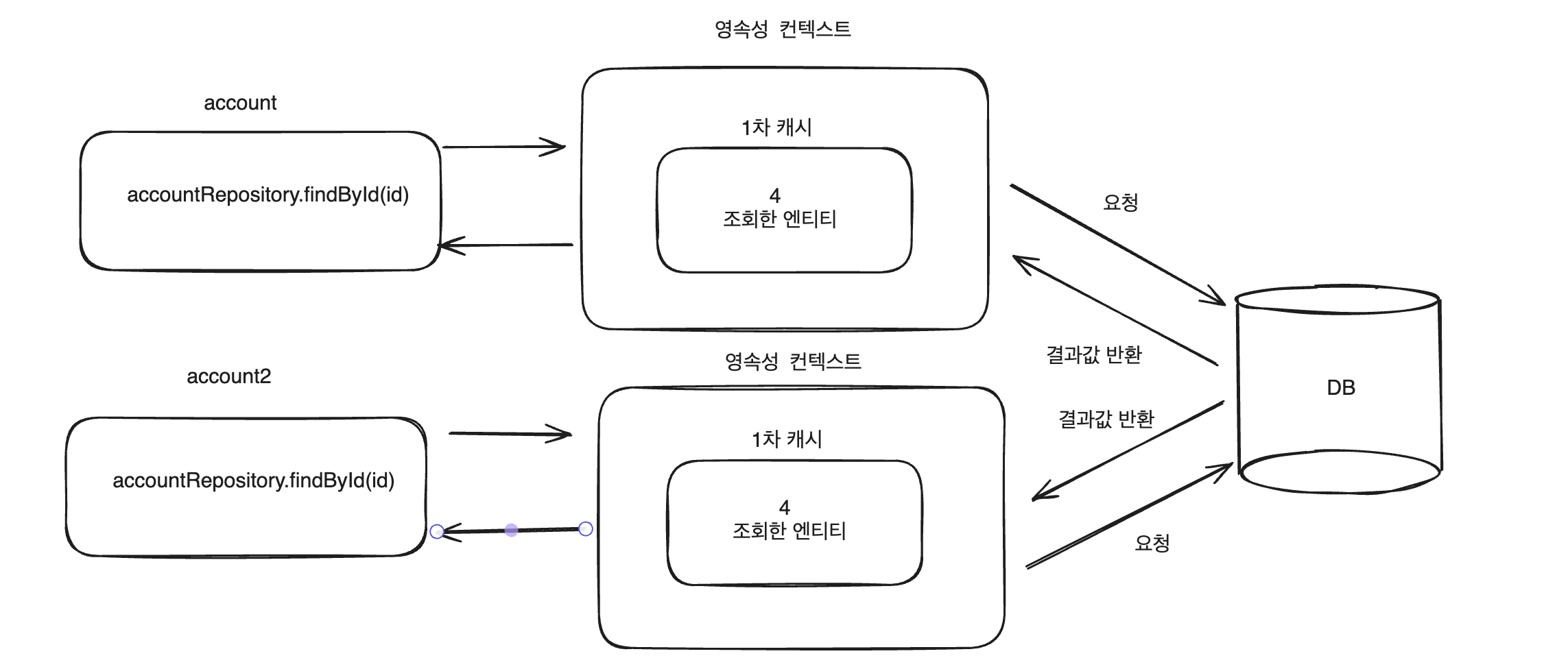
만약 2차 캐시를 적용하지 않고 위에 코드를 실행시키면 id값 1인 account를 조회하는 쿼리는 2번 발생시킵니다.
2번의 쿼리가 발생하는 이유는 각각 Service 코드에서 findById를 할 때 account, account2는 각각의 트랜잭션으로 관리가 되어 각자 다른 영속성 컨텍스트에 관리되고 있기 때문에 2번의 쿼리가 발생합니다.
2차 캐시 적용 안되었을 때 동작 과정

2차 캐시 적용
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-cache'
implementation 'org.ehcache:ehcache:3.10.0'
implementation 'org.hibernate:hibernate-jcache:6.0.2.Final'
implementation 'javax.cache:cache-api:1.1.1'
spring:
jpa:
hibernate:
ddl-auto: create
properties:
hibernate:
show_sql: true
cache:
use_second_level_cache: true
factory_class: org.hibernate.cache.jcache.internal.JCacheRegionFactory
javax:
persistence :
sharedCache:
mode: ENABLE_SELECTIVE
import org.hibernate.annotations.Cache;
import org.hibernate.annotations.CacheConcurrencyStrategy;
@Entity
@Cache(usage = CacheConcurrencyStrategy.READ_ONLY)
@Getter
public class Account {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private int age;
public Account(String name, int age) {
this.name = name;
this.age = age;
}
protected Account() {
}
}
2차 캐시를 적용하고 동일하게 테스트코드를 실행시키면 적용하지 않을 때와 다르게 account를 조회하는 쿼리가 1번만 발생됩니다.
2차 캐시 적용 되었을 때 동작 과정
2차 캐시에 조회하려는 엔티티가 없을 때
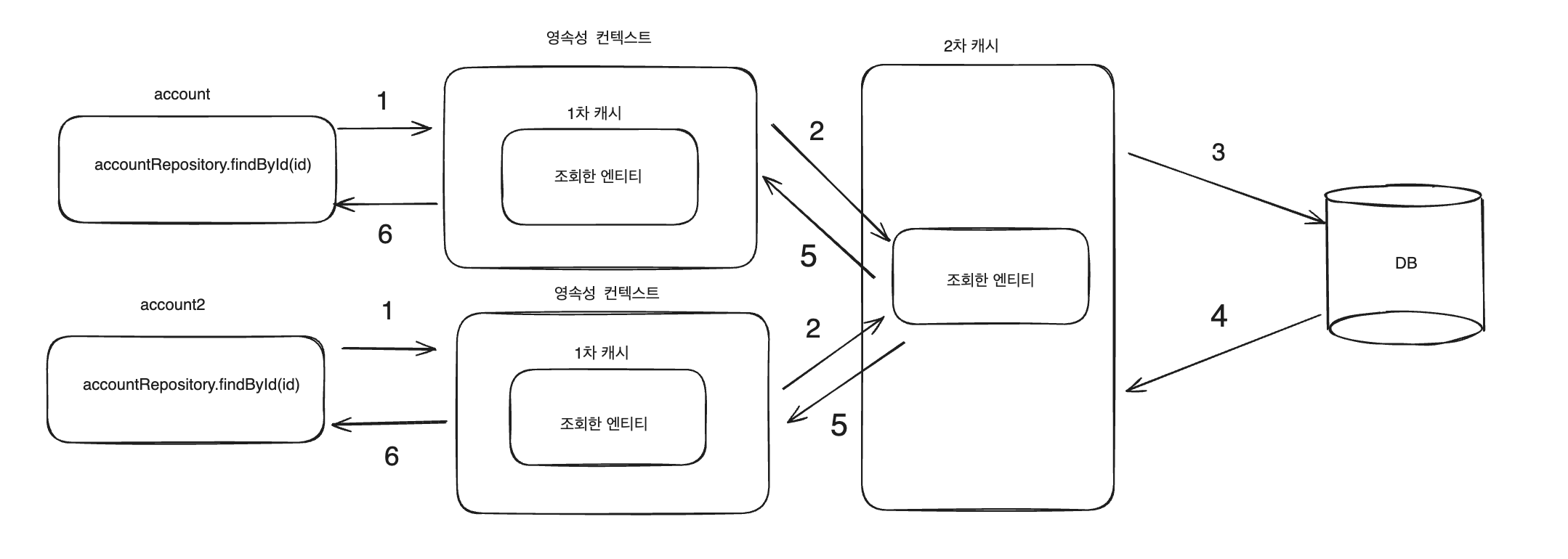
- account 엔티티를 조회하려고 시도합니다.
- 영속성 컨텍스트의 1차 캐시를 보고 조회하려는 엔티티가 없으면 2차 캐시에 요청합니다.
- 2차 캐시에서 조회하려는 엔티티가 없으면 데이터베이스에 접근합니다.
- 데이터베이스에서 조회하려는 데이터를 반환해 줍니다.
- 2차 캐시는 데이터베이스에서 반환받은 데이터를 1차 캐시로 반환해 줍니다.
- 1차 캐시는 조회하려는 엔티티를 최종으로 반환해 줍니다.
2차 캐시에 조회하려는 엔티티가 있을 때

- account 엔티티를 조회하려고 시도합니다.
- 영속성 컨텍스트의 1차 캐시를 보고 조회하려는 엔티티가 없으면 2차 캐시에 요청합니다.
- 2차 캐시에 조회하려는 엔티티가 있으면 데이터베이스에 접근하지 않고 2차 캐시에서 1차 캐시로 바로 반환해 줍니다.
- 1차 캐시는 조회하려는 엔티티를 최종으로 반환해 줍니다.

2차 캐시를 사용했을 때 이점 및 주의할 점
이점
- 영속성 컨텍스트가 다르더라도 같은 엔티티를 조회를 해올 때 데이터베이스 접근 횟수를 줄일 수 있습니다.
- 캐시에 담긴 객체를 바로 반환하는 게 아닌 복사본 만들어서 반환하기 때문에 동시성 이슈를 방지할 수 있습니다.
주의할 점
- 2차 캐시에서 조회를 하는 엔티티는 복사본을 반환해 주기 때문에 동일성 보장을 해주지 않습니다.
@Cache 속성
- useage : CacheConcurrencyStrategy를 사용해서 캐시 동시성 전략을 설정합니다.
- READ_ONLY : 조회가 주로 이루어지며 수정이 일어나지 않을 때 사용하는 것이 적합합니다.
- READ_WRITE : 조회 및 수정 작업을 할 때 사용하는 것이 적합합니다. Phantom Read가 발생할 수 있으므로 SERIALIZABLE 격리 수준에서는 사용할 수 없습니다.
- NONSTRICT_READ_WRITE : 수정 작업을 하지 않는 데이터에 적합합니다.
- NONE : 캐시를 설정하지 않습니다.
- TRANSACTIONAL : 컨테이너 관리환경에서 사용할 수 있습니다. 설정에 따라 격리 수준인 REPETABLE_READ를 보장받을 수 있습니다.
'JPA' 카테고리의 다른 글
| [JPA] Fetch Join의 양면성 (1) | 2024.05.28 |
|---|---|
| [JPA] JdbcTemplate과 JPA 데이터 Insert 속도 비교 (2) | 2023.06.09 |
| [JPA] Cascade 옵션 종류 및 예제 (0) | 2023.04.12 |
| [JPA] Kotlin을 이용하여 Soft Delete 구현 (0) | 2023.03.04 |
| [JPA] N+1 원인 및 해결방법 (0) | 2023.01.18 |