[Redis] 기본 명령어
들어가기 전
이번 포스팅에서는 레디스의 기본 명령어를 예제와 함께 알아보겠습니다.
이번 포스팅을 읽기 전에 캐시와 레디스에 대한 글을 먼저 읽고 이번 포스팅을 이어서 보면 좋을 거 같습니다.
https://hoestory.tistory.com/46
[Redis] Redis 개념 및 특징
들어가기 전 Redis는 Cache와 연관이 되어 있어 Cache에 대해 먼저 알아보고 Redis의 개념과 특징에 대해 알아보겠습니다. Cache란? 자주 사용하는 데이터를 메모리에 미리 복사해 놓는 임시 장소입니다
hoestory.tistory.com
Redis의 자료 구조
레디스에서는 여러 가지 자료구조를 지원을 해줍니다.
- String
- Hashes
- Sets
- Sorted Set
- Bitmaps
- Lists
String
일반적인 문자열을 나타내고 String으로 될 수 있는 바이너리 데이터, JPG 이미지 등 거의 모든 형태로 데이터 저장이 가능합니다.
단순 증감 연산에 사용하기도 좋습니다.
명령어 리스트
| 명령어 | 기능 |
| SET key value | key값으로 value 저장 |
| SETNX key value | 지정한 키값이 없을경우에만 데이터 저장 |
| MSET [key value ...] | 여러개의 데이터를 한번에 저장 |
| MSETNX [key value ...] | 지정한 key가 없는 값들만 한번에 저장 |
| APPEND key value | 데이터를 추가, 지정한 key가 없으면 저장 |
| SETEX key 초 value | 지정한 시간(초) 이후에 데이터 자동 삭제 |
| STRLEN key | 데이터의 바이터수를 리턴 |
| DECR key | key의 값을 -1 감소 |
| DECRBY key count | count만큼 감소 |
| DEL key | 데이터 삭제 |
| GET key | 데이터 조회 |
| GETSET key value | 기존 데이터를 조회하고 새로운 데이터 저장 |
| INCR key | key의 값을 +1 증가 |
| INCRBY key count | count만큼 증가 |
| MGET key1 key2 | 여러개의 데이터를 한번에 조회 |
예제
예제에 들어가기 전에 필자는 Docker를 이용하여 redis를 구축하였습니다.
docker exec -it "레디스컨테이너이름" /bin/sh
위와 같이 뜬다면 아래 명령어를 입력을 합니다.
redis-cli
예제를 따라 하다가 저장된 키가 무엇이 있고 저장된 키를 모두 지우고 싶으면 아래 명령어를 입력하시면 됩니다.
keys * <- 모든 키 조회
flushAll <- 모든 키 삭제
이제 String에 대한 명령어 예제에 대해서 다뤄보겠습니다.
SET test hello
GET test

- SET을 이용하여 test라는 키에 hello 데이터를 저장합니다.
- GET을 이용하여 키에 저장된 데이터를 조회합니다.
MSET first hello second 1234 third A2
MGET first second third

- MSET을 이용하여 여러 개의 키와 값을 저장할 수 있습니다. first, second, third가 키가 되고 hello와 1234, A2가 데이터가 됩니다.
- MGET으로 여러 키에 대한 데이터를 조회할 수 있습니다.
SETNX fisrt abcd
SETNX four abcd
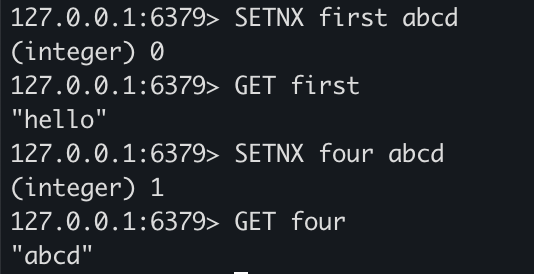
- SETNX는 기존 키값이 존재하면 데이터를 저장하지 않고 새로운 키일 경우에만 데이터를 저장합니다.
SETLEN lenTest
- 저장된 데이터의 크기를 반환합니다.
MSET first abcd second 23 third 23
INCR first
INCR second
DECR third

- first키는 숫자가 아닌 문자로 이루어져 있어 INCR 또는 DECR을 사용하면 에러가 발생합니다.
- second는 INCR을 사용하여 기존에 설정한 값에서 1이 증가되었습니다.
- third는 DECR을 사용하여 기존에 설정한 값에서 1이 감소되었습니다.
MSET first 10 second 10
INCRBY first 5
DECRBY second 5

- INCRBY를 사용하여 증가하고 싶은 만큼 증가시킵니다.
- DECRBY를 사용하여 감소하고 싶은 만큼 감소시킵니다.
Sets
중복된 데이터를 저장하지 않습니다. 자바에서 Set을 생각하면 될 거 같습니다.
데이터가 정렬되지 않은 집합입니다. Set 간의 연산을 지원을 하는데 교집합, 합집합, 차집합을 매우 빠른 시간 내에 추출할 수 있습니다.
| 명령어 | 기능 |
| SADD key value | 집합에 value를 추가 |
| SREM key value | 집합에 value를 삭제 |
| SMEMBERS key | 집합에 모든 value 조회 |
| SCARD key | 집합에 속한 value의 개수를 조회 |
| SISMEMBER key value | 집합에 value가 존재하는지 조회 |
| SUNION key [key...] | 합집합 |
| SINTER key [key...] | 교집합 |
| SDIFF key[key..] | 차집합 |
| SRANDMEMBER key [count] | 집합에서 무작위로 value값 가져옴 |
| SMISMEMBER key value [key value..] | 집합에서 value가 존재하는지 조회, 한번에 여러개 조회 가능 |
SADD first test
SADD first test2
SADD first test
SMBMERS first

- SADD 명령어를 사용하여 first라는 집합에 test, test2, test 데이터를 넣고 SMEMBERS를 사용하여 데이터가 중복 저장이 안 되는 것을 확인할 수 있습니다.
SADD first test
SADD first test2
SCARD first
SMEMBERS first
SREM first test
SCARD first
SMEMBERS first

- SADD를 통해 넣고 집합의 개수를 SCARD로 확인할 수 있습니다.
- SREM은 집합의 값을 삭제할 수 있습니다.
SISMEMBER test
SISMEMBER test2

- 집합에서 찾으려는 값이 존재하면 1 존재하지 않으면 0을 반환합니다.
SADD first test
SADD first test2
SADD second exam
SADD second test2
SUNION first second
SINTER first second
SDIFF first second

- SUNION을 이용하여 두 집합의 합집합 결과를 반환합니다.
- SINTER를 이용하여 두 집합의 교집합 결과를 반환합니다.
- SDIFF를 이용하여 두 집합의 차집합 결과를 반환합니다.
SRANDMEMBER first
SRANDMEMBER first
SRANDMEMBER first
SMISMEMBER first test test2 test3

- SRANDMEMBER은 집합에 포함되어 있는 값들 중 랜덤으로 값을 반환합니다.
- SMISMEMBER은 집합 안에 value값들이 존재하면 각각 1, 존재하지 않으면 0을 반환합니다.
Sorted Sets
Sets 자료구조와 달리 score라는 필드를 추가하여 score 기준으로 오름차순으로 데이터를 정렬합니다.
Sets처럼 중복된 데이터를 저장할 수 없지만 score 값은 중복될 수 있습니다.
만약 score 값이 같다면 사전순으로 정렬합니다.
| 명령어 | 기능 |
| ZADD key score value [key score value ..] | 집합에 score와 value를 추가 |
| ZCARD key | 집합에 저장되어 있는 key의 데이터개수를 조회 |
| ZINCRBY key score증가값 value | score 증가 |
| ZRANGE key start stop | 인덱스 범위를 지정하여 조회 |
| ZRANGEBYSCORE key min max | score값 범위를 지정하여 조회 |
| ZREM key value | 집합에서 value값 삭제 |
| ZREMRANGEBYSCORE key min max | score값 범위를 이용하여 value값 삭제 |
| ZSCORE key value | value를 지정하여 score 조회 |
| ZCOUNT key min max | score로 범위를 지정하여 개수 조회 |
| ZRANK key value | value를 지정하여 index 조회 |
| ZREVRANK key value | value를 지정해서 reverse index 조회 |
| ZREMRANGEBYRANK key start stop | index 범위를 지정하여 value 삭제 |
| ZPOPMIN key | 작은값부터 삭제 |
| ZPOPMAX key | 큰값부터 삭제 |
ZADD first 10 A second 20 B third 10 C
ZRANGE first 0 2

- ZADD 명령어를 이용하여 first 키 이름을 가진 집합 안에 데이터를 삽입하였습니다.
- ZRANGE를 사용하여 집합 안에 들어있는 데이터를 조회할 수 있습니다.
- score 기준으로 데이터가 정렬이 되어있고 score값이 같다면 사전순으로 정렬합니다.
ZINCRBY first -1 C
ZRANGE first 0 2
ZINCRBY first 11 A
ZRANGE first 0 2

- ZINCRBY를 이용하여 score값을 증가시킬 수 있고 감소시킬 수 있습니다.
- C값을 -1을 하면 C의 scorer값은 9가 되어 0번째 인덱스에 존재하는 것을 위에 사진에서 확인할 수 있습니다.
- A값을 +11 하면 A의 score값은 21이 되어 B의 score값인 20보다 커서 2번째 인덱스에 존재하는 것을 확인할 수 있습니다.
ZSCORE first A
ZSCORE first B
ZSCORE first C
ZRANGEBYSCORE first 9 20
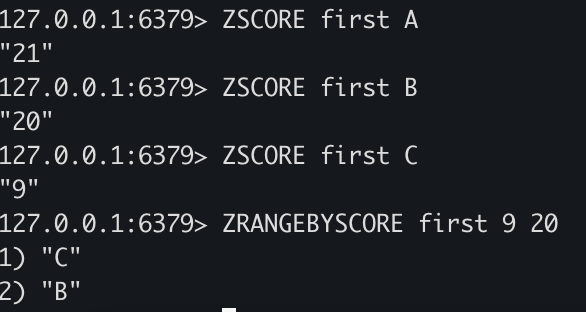
- ZSCORE로 각각의 value의 score값을 조회할 수 있습니다.
- ZRANGEBYSCORE로 score 범위를 지정하여 value값을 조회할 수 있습니다.
ZREM first B
ZRANGE first 0 2
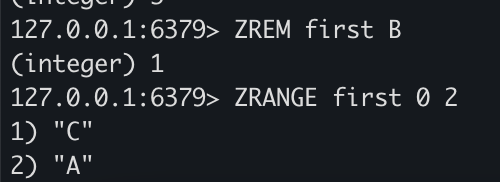
- ZREM을 통해 B의 값을 가진 데이터를 삭제할 수 있습니다.
ZADD first 21 A 20 B 9 C
ZPOPMIN first
ZPOPMAX first
ZRANGE first 0 2

- ZPOPMIN은 제일 작은 값을 삭제합니다. 제일 작은 값 C가 삭제된 것을 확인할 수 있습니다.
- ZPOPMAX는 제일 큰 값을 삭제합니다. 제일 큰 값 A가 삭제된 것을 확인할 수 있습니다.
ZADD first 21 A 20 B 9 C
ZCOUNT first 9 20
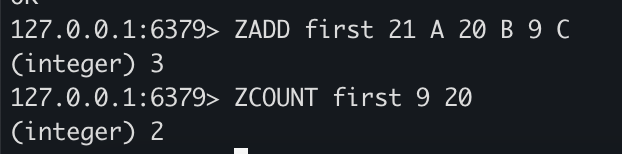
- ZCOUNT로 score의 범위를 지정하여 범위에 속한 데이터 개수를 조회할 수 있습니다.
Lists
Array 형식의 데이터 구조를 가지고 데이터를 삽입한 순서대로 저장됩니다. 추가, 삭제, 조회하는 것은 O(1)이지만 특정 index 값을 조회할 때는 O(N)의 속도 가지게 됩니다. 즉 추가 삭제는 빠르지만 인덱스 접근은 느립니다.
Queue와 Stack으로 사용할 수 있습니다.
| 명령어 | 기능 |
| LPUSH key value [value ..] | 왼쪽에서 데이터 저장 |
| RPUSH key value [value ..] | 오른쪽에서 데이터 저장 |
| LPOP key | 리스트 왼쪽에서 데이터 꺼내고 삭제 |
| RPOP key | 리스트 오른쪽에서 데이터 꺼내고 삭제 |
| LLEN key | 리스트의 데이터 총 개수 조회 |
| LRANGE key start stop | 인덱스로 범위를 지정하여 리스트 조회 |
| LINEX key index | 인덱스로 특정 위치의 데이터 조회 |
| LSET key index value | 특정 인덱스로 데이터 이동 |
| LREM key count value | 값을 지정해서 삭제 |
| LREVRANGE key start stop | 인덱스 범위를 지정해서 역순으로 조회 |
| LINSERT key BEOFRE|AFTER pivot value | 지정한 값 앞 또는 뒤에 새 값 저장 |
| LPUSHX key value | 기존에 리스트가 있을경우에만 왼쪽에서 데이터 저장 |
| RPUSHX key value | 기존에 리스타가 있을경우에만 오른쪽에서 데이터 저장 |
LPUSHX first 1
RPUSHX first 1
LPUSH first 1
RPUSH first 2
RPUSHX first 1
LPUSHX first 3
LLEN first
LRANGE first 0 3

- LPUSHX, RPUSHX는 기존 리스트가 존재해야 데이터를 삽입할 수 있습니다. 기존 리스트가 없는데 해당 명령어를 사용할 시 0을 반환합니다.
- RPUSH를 하면 오른쪽에서 데이터를 삽입합니다.
- LPUSH를 하면 왼쪽에서 데이터를 삽입합니다.
- LLEN를 사용하면 리스트의 크기를 반환하고 LRANGE를 사용하여 인덱스 범위를 지정하면 지정한 만큼 반환합니다.
Stack
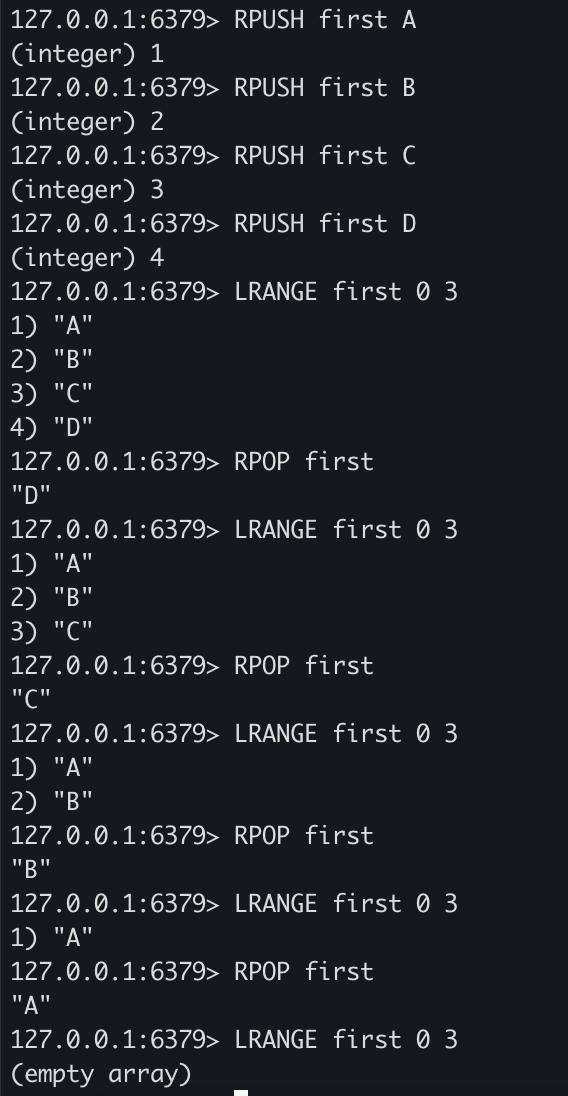
RPUSH first A
RPUSH first B
RPUSH first C
RPUSH first D
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first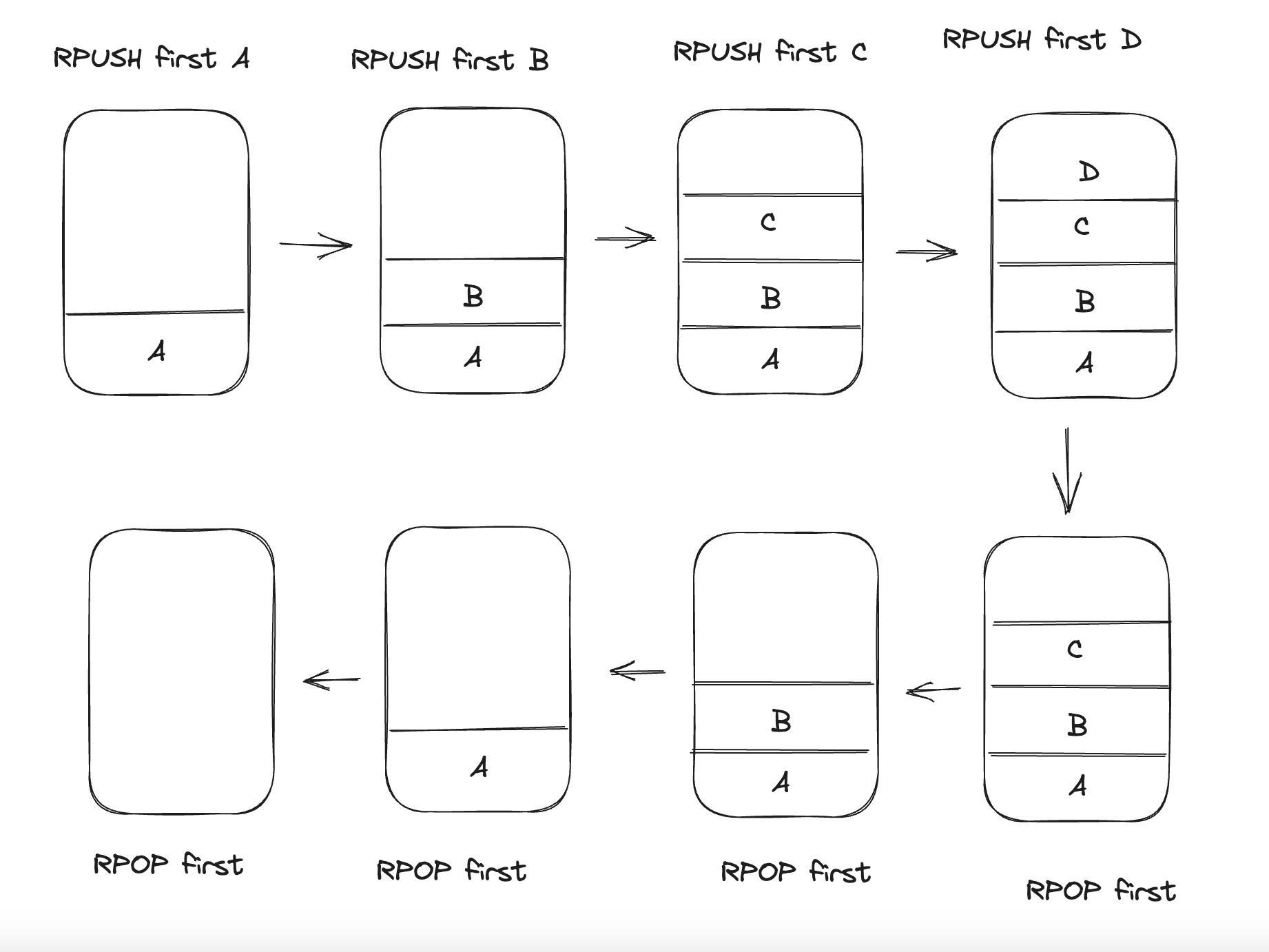
- Stack의 특징은 LIFO 방식입니다.
- RPUSH로 오른쪽으로 데이터를 삽입하고 RPOP를 사용하여 오른쪽에서 데이터를 꺼내면서 제거합니다.
Queue
LPUSH first A
LPUSH first B
LPUSH first C
LPUSH first D
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
LRANGE first 0 3
RPOP first
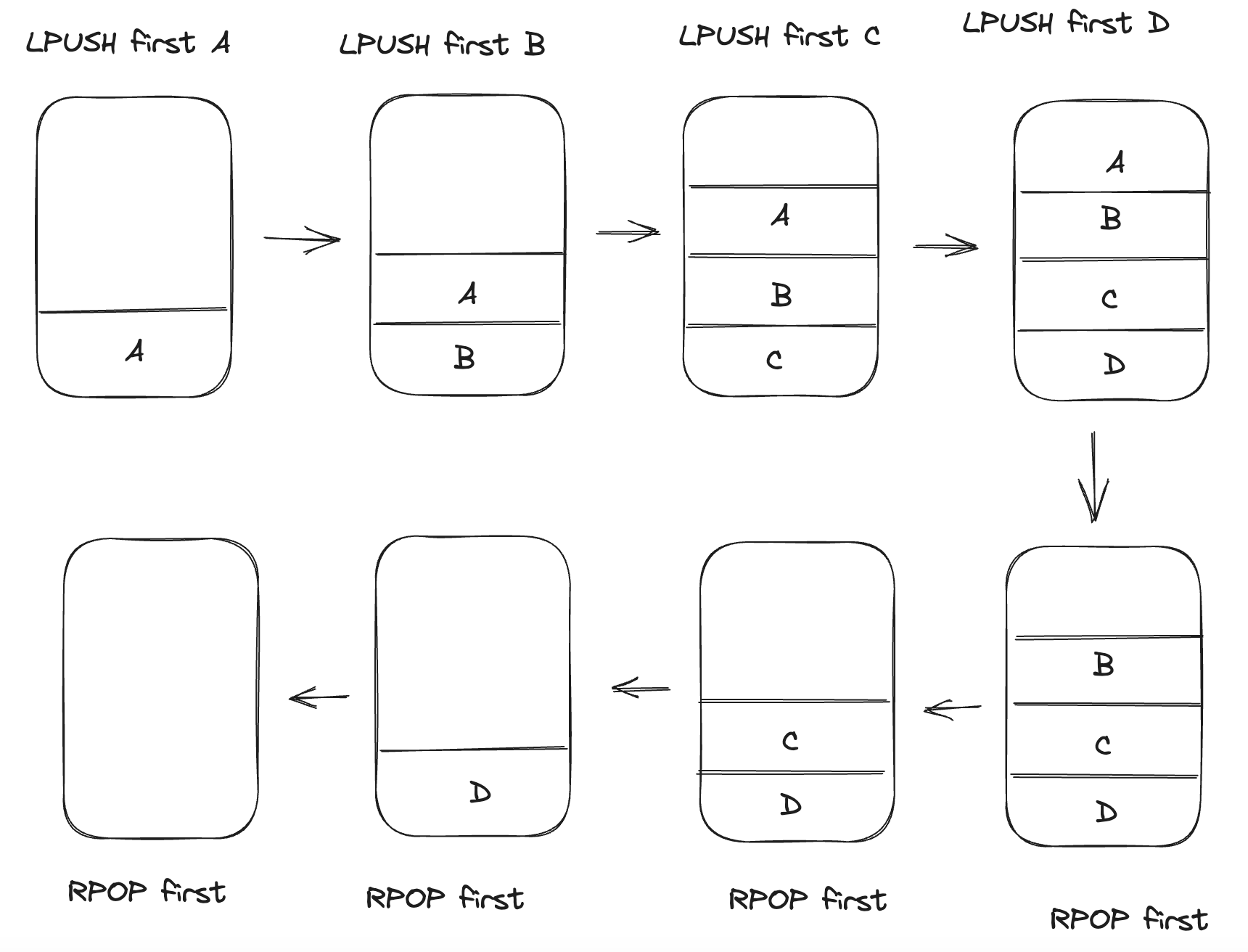
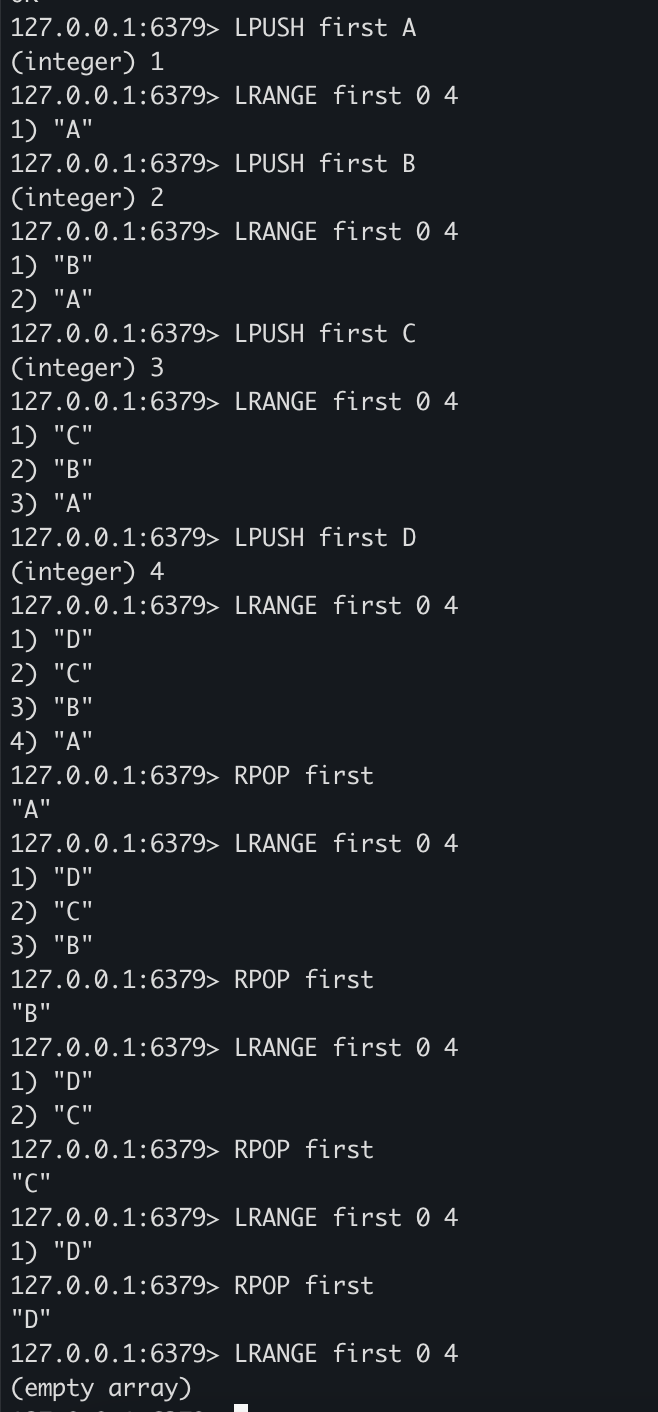
- Queue의 특징은 FIFO 방식입니다.
- LPUSH를 사용하여 왼쪽에서 데이터를 삽입하고 RPOP를 사용하여 오른쪽에서 데이터를 꺼내면서 제거합니다.
LPUSH first A
RPUSH first B
LPUSH first B
LPUSH first C
RPUSH first A
LREM first 0 B
LREM first 1 A

- LREM 명령어는 LREM key count value 형식인데 여기서 count가 0이면 value와 매칭되는 모든 값을 삭제를 합니다. 그래서 B는 모두 삭제되고 A 같은 경우는 count를 1로 지정해서 하나만 삭제됩니다. 삭제는 왼쪽부터 삭제됩니다.
LPUSH first G
LPUSH first E
LPUSH first D
LPUSH first B
LPUSH first A
LRANGE first 0 4
LINSERT first AFTER B C
LRANGE first 0 5
LINSERT first BEFORE G F
LRANGE first 0 6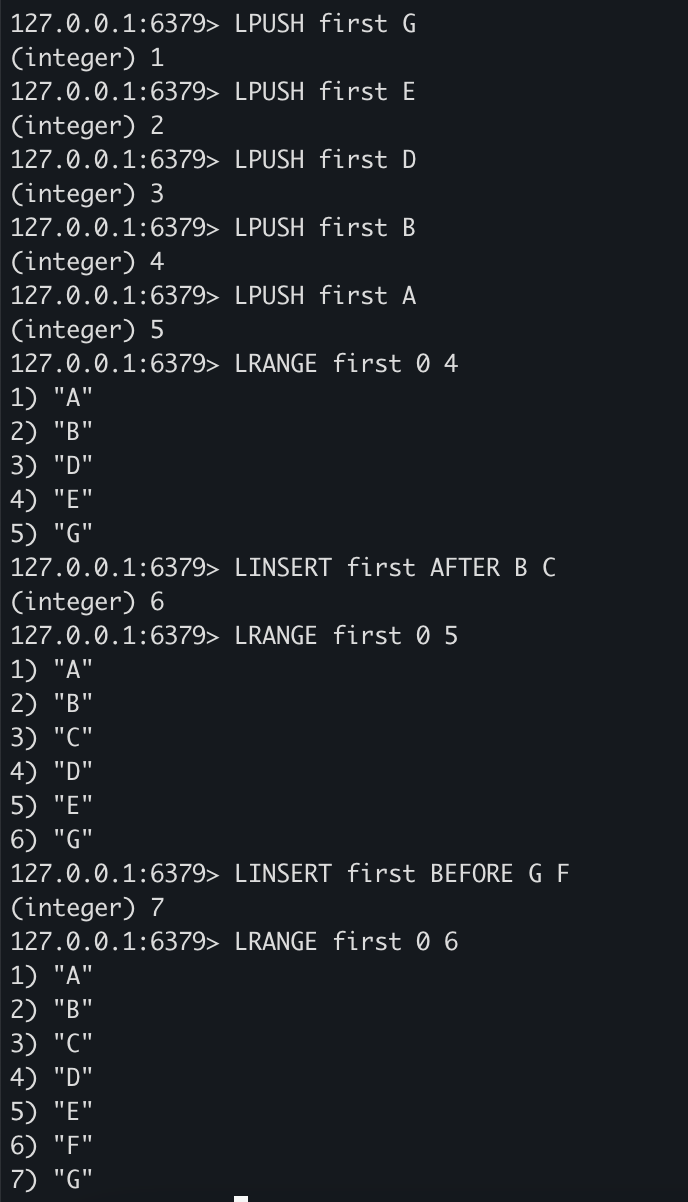
- LINSERT의 옵션 BEFORE를 사용하면 지정한 value값의 앞 인덱스에 데이터를 삽입합니다.
- AFTER를 사용하면 지정한 value값의 뒤 인덱스에 데이터를 삽입합니다.
LINDEX first 4
LSET first 4 HI
LRANGE first 0 6
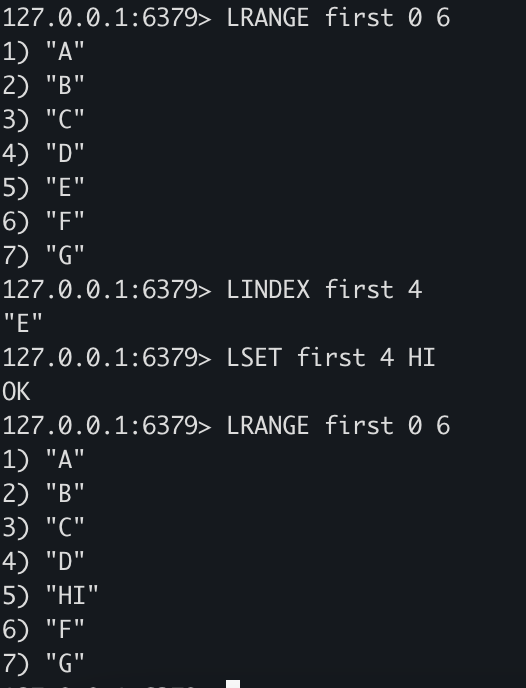
- LINDEX를 사용하여 특정 인덱스의 value값을 조회할 수 있습니다.
- LSET을 통해 특정 인덱스의 데이터를 수정할 수 있습니다.
Hashes
하나의 key 하위에 "필드 : 값" 쌍을 저장할 수 있습니다. JSON 형태와 유사합니다.
| 명령어 | 기능 |
| HSET key field value | 필드와 값을 저장 |
| HMSET key field value [field value ..] | 여러개의 필드와 값을 저장 |
| HDEL key field [field..] | 특정 field로 값 삭제 |
| HGET key field | 필드로 값 조회 |
| HMGET key field [field..] | 여러개의 값 조회 |
| HLEN key | 필드로 개수 조회 |
| HEXISTS key field | 필드가 존재여부 확인 |
| HGETALL key | key에 속한 모든 필드와 값 조회 |
| HKEYS key | Key에 속한 모든 필드 이름 조회 |
| HVALS key | key에 속한 모든 값 조회 |
| HSETNX key field value | 기존 필드가 존재하지 않으면 값 저장 |
| HSTRLEN key field | 값의 길이 조회 |
| HINCRBY key field increment | 필드의 값을 increment만큼 증가 또는 감소 |
HSET human name test
HGET human name
HMSET human age 25 gender MALE
HMGET human name age gender
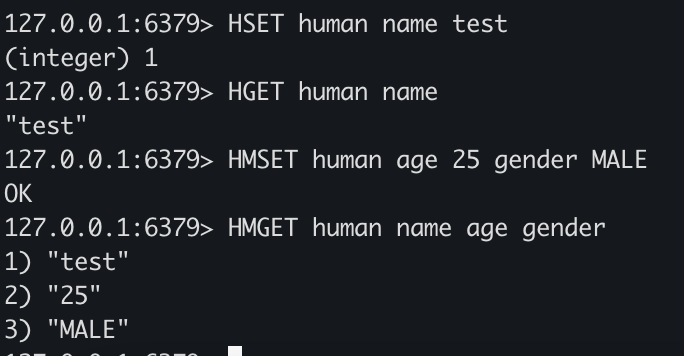
- HSET으로 단일 필드값을 저장하고 HGET을 통해 단일 필드값을 조회할 수 있습니다.
- HMSET으로 여러 필드값을 저장하고 HMGET을 통해 여러 필드값을 조회할 수 있습니다.
HLEN human
HVALS human
HKEYS human
HGETALL human
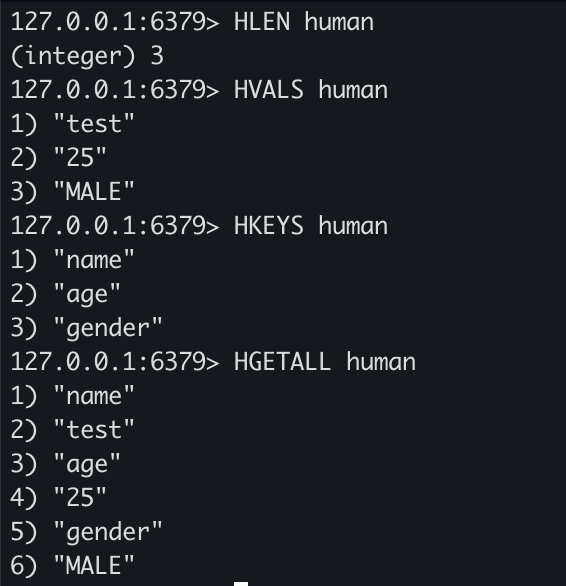
- HLEN을 통해 key에 속한 필드의 개수를 조회할 수 있습니다.
- HVALS는 key의 모든 값들을 조회하고 HKEYS는 키의 모든 필드값을 조회할 수 있습니다.
- HGETALL은 key의 필드와 값을 모두 조회할 수 있습니다.
HEXISTS human phone
HEXISTS human name

- HEXISTS를 사용하여 key에 속하는 필드일 경우에 1을 반환하고 속하지 않으면 0을 반환합니다.
HINCRBY human age 1

- HINCRBY에서 값을 1로 하여 1이 증가하였습니다. -1을 하면 감소하고 2를 하면 2가 증가됩니다.
HSTRLEN human name
- 문자열의 크기를 반환합니다.
Bitmaps
Bitmaps은 String의 변형이고 bit 단위로 연산이 가능합니다. String이 512MB를 저장할 수 있듯이 2^32 bit까지 사용이 가능합니다.
저장할 때 공간을 절약할 수 있는 장점이 있습니다.
| 명령어 | 기능 |
| SETBIT key offset value | bit값 저장 |
| GETBIT key offset | bit값 조회 |
| BITCOUNT key [start end] | bit값이 1인 bit개수 조회 |
SETBIT eat 2 1
GETBIT eat 2
GETBIT eat 1
BITCOUNT eat
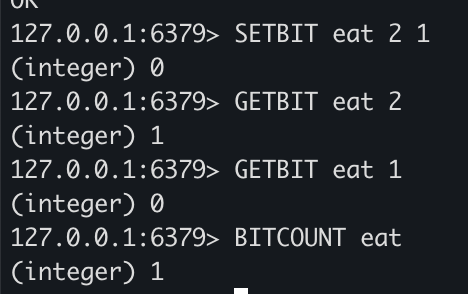
- SETBIT를 통해 특정 offset의 값을 저장하고 BITCOUNT로 bit값이 1인 개수를 조회할 수 있습니다.
'Redis' 카테고리의 다른 글
| [Redis] Spring Boot + Docker-Compose + Redis + Session을 이용한 로그인 (0) | 2023.02.01 |
|---|---|
| [Redis] Redis 개념 및 특징 (1) | 2023.01.27 |